Data Transforms in Chemometric Calibrations: Variation in MLR, Part 3: Reducing Sensitivity to Repack Σbi = 0
In this column, we examine a variation of the MLR algorithm that reduces sensitivity to repack variations in the special case that the absorbance at all wavelengths used in the calibration model undergo the same change when repacked.
Correction to past columns: We apologize to those of our readers who have no difficulty in counting beyond 1 even without their computers. Your authors, on the other hand, seem to have run into some difficulties in that regard, even WITH our computers. The first two parts of this “Data Transforms” sub‐series were published in the February 2022 and July 2022 issues of Spectroscopy (1,2). However, both columns designated themselves “Part 1” of the sub‐series in print; this has been corrected for the online versions as denoted in the reference section.
As mentioned in our previous column (2) on the topic of data transforms, here we examine transformations of spectral data that have the goal of improving calibration performance. Not all transformations, however, are designed specifically to produce that result, although that often occurs as a “side effect” to the algorithm used. Similarly, while some data transforms can be applied to the data independently of the calibration algorithm used to create the ultimate calibration model, some transforms are more usefully applied before a particular calibration algorithm is applied. This column is based on the talk given at the 2020 Gold Medal Award session at EAS when that award was conferred on your columnists (3).
More Variations of the MLR Algorithm
Variation #2 of MLR: Σbi = 0 (i ≠0)
What does this mean, and why would we want to do it?
For most of its existence, and especially in the early days of modern NIR analysis, the technology has been applied to solid samples. Not just solid blocks of material, but granulated materials and powders. Powders have at least one distinctive characteristic: it can never achieve an exact repeat spectral reading when you re-measure a sample. The reason for that characteristic is very simple: the multitude of small particles in a powdered sample cannot be exactly reproduced because the particles are in different places and in different orientations, and therefore interact differently with the illuminating beam upon performing the re-reading. The resulting effect on the spectral data is that readings at different wavelengths are offset by uncontrolled and uncontrollable amounts, giving spectral displays that are similar to each other, but different in the details. These offsets are variously called the “Particle size Effect”, or the “Repack Effect”, in the literature. Numerous examples of this effect can be seen in the Applications sections of any of the editions of the Handbook of Near‐Infrared Analysis (4), or prior editions, as well as in other texts dealing with this subject, and applications articles in specialized journals. There is even an example in the previous column in this sub-series (2). These offsets are in addition to, independent of, and often larger than the variations in the spectra due to differences in the composition of the samples.
We present the analogy of a thermometer: before you can use a thermometer to make measurements of temperature, it must be calibrated. In the case of a thermometer, it is typically calibrated by putting it in an ice bath where you know the temperature is zero degrees C, and mark that point on the scale. Then you put it in a steam bath where you know the temperature is 100 degrees C, and put a mark on the scale corresponding to that. Now you can use the thermometer to read any temperature between those values, and with care and luck, even slightly beyond the marks. In order to do all that, however, you must also make some assumptions about the behavior of the thermometer, particularly that the thermometer reading is a linear function of the actual temperature.
So it is with NIR. Although somewhat more complicated to perform, the underlying concept and process is the same. Any instrument reading is meaningless in isolation. To give it meaning we have to somehow relate the instrument readings, represented by the spectra of the samples, to accurately known composition values. The process is somewhat more complicated than calibrating a thermometer, but the concept is the same: we need to have both the instrument readings (spectral data values) and the known (or “actual”) values of the composition variables in order to determine the relationships between them.
It doesn’t really matter what the original purpose of collecting the data is, as long as you wind up with all of it (spectra and composition). The original purpose of collecting a “prediction (or “validation”) set”, for example, is usually to verify the accuracy of the calibration model being used. In order to do that, you need to have accurate values for the composition of the samples (at least for the analyte of interest) so you can make the comparison. Then you can compare the instrument “predictions” to the known analyte values, and determine (in a “statistical” sense) the accuracy of the calibration model. But when you have both the spectra and the known analyte values, you can work the same data the other way and use the data to describe the relationships between them; that’s the NIR calibration process.
But NIR spectra, especially of particulate solid samples, have a complication that a thermometer doesn’t have. Because of the randomness inherent in the nature of particulate samples, oftentimes you can get a different set of spectral readings from two different portions of the same sample (as a result of the repack effect), even though they both correspond to the same sample composition.
For as long as NIR has been a popular analytical technique, that effect has shown up as differences in the predicted values of the analyte when the different portions were measured, a consequence of the differences in the measured spectra. Ever since Karl Norris described the new technology that we now know as modern NIR analysis, the community has sought an algorithm that would give the same predicted value for an analyte even in the face of the spectral differences that result from measuring two different portions of the same sample.
A typical example of the repack effect is shown in Figure 2 of our previous column (2). It is noteworthy that the spectral variations due to the repack phenomenon are systematic across the spectrum, but the magnitude of the effect varies both with wavelength and with the absorbance of the sample. Attempts to derive mathematical descriptions of these variations from first principles based on properties of the sample have, in general, been unsuccessful, despite many scientists attacking that problem for over 100 years (see [5,6], Kortum [7], Wendlandt, et al. [8], recently by Dahm [9] and more recently by Meyerhofer [10] [the “Dahm” reference also includes a nice review of the field over the years]).
The problem with having a sample set that exhibits repack variation is that when the data is included in a calibration model, such as in this generalized case:

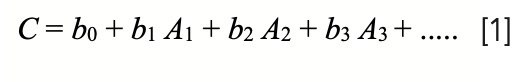
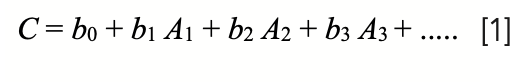
where C is the concentration of analyte computed by the model; Ai is the sample’s absorbance at the ith wavelength; and bi are the calibration coefficients. The different absorbance values result in different predicted values for portions of the same sample.
The standard solution of these equations, that results in the standard MLR algorithm, is achieved by converting the equations to matrix formulation:

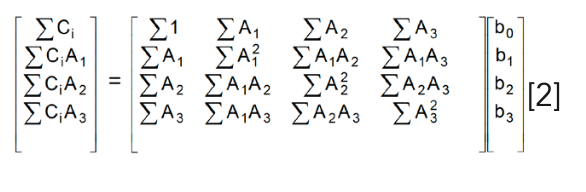
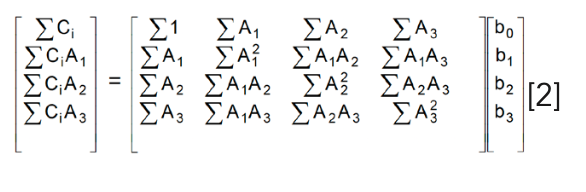
and then solving those equations for b, the calibration coefficients (in shorthand notation – see chapter 4 in [11] and the solution here is expressed in compact matrix notation:

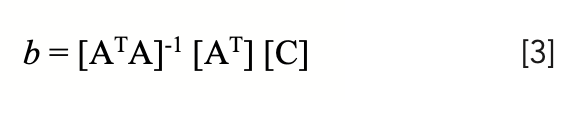
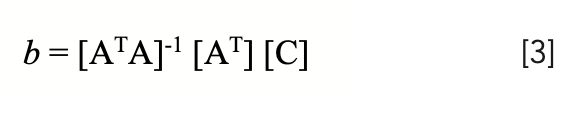
The repack effect exhibits itself as a change in the value of C computed from spectra where the absorbances change due to the purely physical action of the sample being repacked into the sample cup:

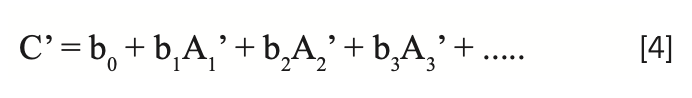
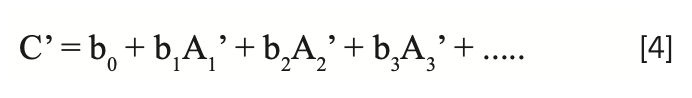
where the primed variables represent the absorbances and predicted concentration values calculated after the sample was repacked.
Therefore, for any sample subject to the effect of repack, a different value of the analyze will be computed for the two cases, even though they represent the same sample. Subtracting the result of one set of readings from the other, we obtain:

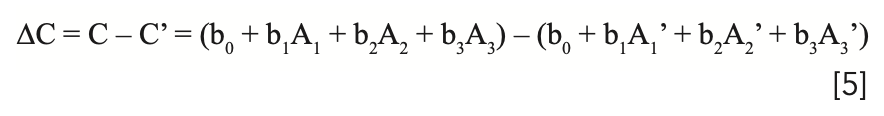
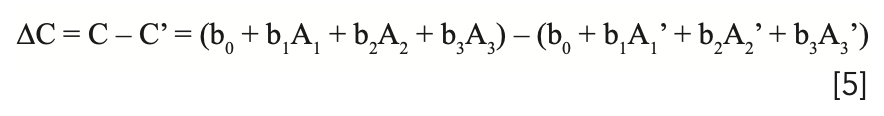
We can rearrange the terms and factor:

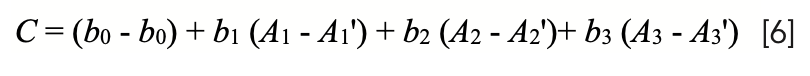
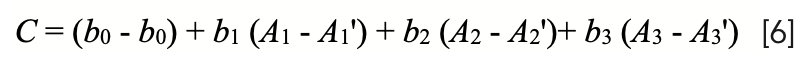
Noting that b0 - b0 = 0, we arrive at:

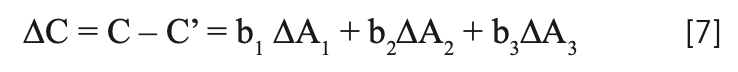
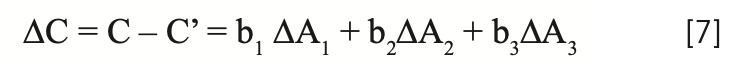
where ∆Ai represents the change in absorbance at the ith wavelength (that is Ai - A’i), due to the changes in the sample surface attendant upon the repacking. The desire, therefore, is to create calibration models that not only would allow instruments to accurately analyze future samples (“unknown” samples at the time the calibration model was being generated), but that would also resist changes in the predicted analytical values when the sample was repacked during routine measurements. For this purpose, many ad hoc data transforms were applied to spectral data sets. Out of all that empirical work, certain data transforms became popular, primarily transforms involving spectral “derivatives” (dA/dλ). In particular, “second derivative” transforms (d2A/dλ2) came to be used to a large extent. This was not because anyone demonstrated any special merit to that data transform, but simply because instrument manufacturers and software manufacturers built it into their calibration software, and it worked “well enough”. After all, given several values of SEP, one of them has to be the smallest. But spectral derivatives have another problem: they can be used when continuous (or at least quasi-continuous spectra are available), but see the critique of the “derivative” transform in our previous column (2), and in any case, “derivatives” cannot be calculated when readings at separated individual wavelengths are measured, such as when instruments with fixed interference filters are used to select the wavelengths.
There is a special case of equation 7 that is of interest here, which provides an alternative to the use of spectral derivatives. It rarely happens exactly, but there are cases where it happens closely enough that the various ∆Ai are all approximately equal. When this occurs, and the approximation of the variations to uniformity are sufficiently close, then we can replace all the ∆Ai with a single value of ∆A to represent the change in absorbance due to repack, as shown in equation 8. Arguably, this approach is not so much a transformation of the data as it is a modification of the MLR algorithm. The data does indeed get modified, but the changes are internal to the algorithm, and the modified data are normally not made accessible outside the program. Of course, anyone who can write their own calibration software can implement any variation they would like. Note that we configure the equation to illustrate the use of three wavelengths in the calibration model. Three wavelengths are sufficient to demonstrate the desired pedagogical requirements without overloading the process with excess symbology and confusion.

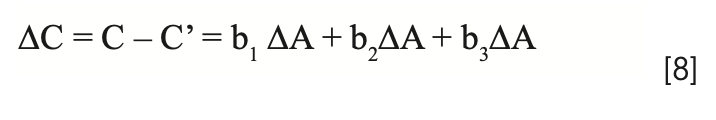
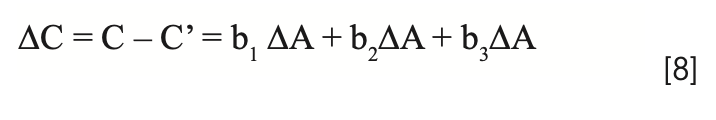
We can now factor the right-hand side of equation 8 as follows:

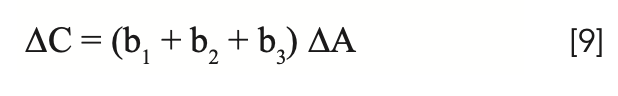
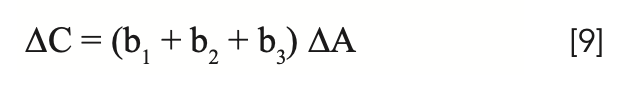
and in this case, if the sum of the calibration coefficients in equation 8 (excluding b0) is zero, then ΔC is also zero, which means that there is no change to the computed analytical value of analyte concentration regardless of any changes of the spectra due to the repack effect.
This result can be used in a number of different ways. First, and simplest, once the standard regression calculations have been performed and the calibration coefficients have been determined, the coefficients can be added together, and the sum reported. This has been previously proposed and designated as the Index of Systematic Variation (see pages 57 and/or 98 in [12]). It serves as an indicator of the sensitivity of the predictions from the model to variations due to repack.
Second, we can seek mathematical ways to compute calibration coefficients that comprise a model that has that property. In addition to being least-square estimators of the reference values of the analyte, the coefficients sum to zero. This is a special case of a more general mathematical concept of applying constraints to the solution of a defined problem. This concept was devised by the Italian mathematician Joseph-Louis Lagrange (1736–1813) (13). Lagrange is famous for many contributions to mathematics, including defining what are now known as the five Lagrangian points of stability in astronomy (special solutions to the “three-body problem”). He also developed the concept and use of what is now called the Lagrange Multiplier. There are general approaches to implementing the concept, which are described in appropriate books on mathematics; for an example, see reference 14. But this column is neither a book on advanced mathematics nor a general discussion of the use and application of constraints, so we will just go directly to the discussion of how we apply those concepts to creating a calibration model whose coefficients sum to zero, in order to minimize the effect of repack on NIR readings.
Taylor (14) devotes an entire section of his book (starting on page 193) to finding solutions to various types of problems subject to constraints. The objective we have here, which is to find NIR calibration coefficients such that the sum of the coefficients equals zero, is addressed through the use of what is known as the Lagrange method of undetermined multipliers, which is discussed on page 198 (14). To implement this, we start with equation 8, and form the sum of squares to be minimized as is normally done:

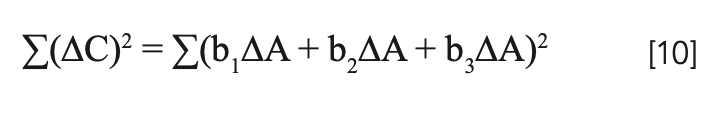
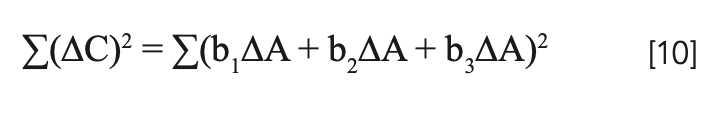
Again, note that we couch our discussion in terms of a three-wavelength model, although the extension to any number of wavelengths is straightforward.
We then add the desired constraint (Σ(bi)= 0) to that sum of squares in the following form:

where λ represents the undetermined Lagrange multiplier. Note that our use of λ here should not be confused with our previous use of λ to indicate wavelengths. Mathematicians are not spectroscopists! A key aspect of using this formulation of adding the constraint in the form used to the sum-of-squares calculation, is that since b1 + b2 + b3 will ultimately be equal to zero, adding that expression to the sum of squares does not change or otherwise affect that sum of squares.
From this point on, we minimize the sum of squares by following the usual procedure of taking the derivative with respect to each of the variables, including λ, and then setting those derivatives equal to zero, just as we did with equation 3 to form the usual regression equations. The resulting matrix equation, corresponding to equation 6 in reference 2 (not the equation 6 in this column) is:

The procedure for deriving equation 12 is described in full detail in chapter 12 of reference 4.
Note several key points about equation 12:
- The constraint added a row and a column to the [ATA] matrix, in addition to adding a row to each of the other two matrices in equation 12.
- The upper-left-hand portion of the [ATA] matrix in equation 12 is the same as equation 6 in reference (4). This section represents the Least-Square calculation of the coefficients.
- The last row and last column of the [ATA] matrix in Equation 12 represent the inclusion of the constraint.
The 1’s are each multiplied by the corresponding b’s, and their sum must equal the last entry of the [CAT] matrix on the LHS of equation 12, which is zero. Equation 12 represents a set of simultaneous equations that need to be solved. Since one of the equations included as one of the simultaneous equations is the one that specifies (from equation 9) Σbi = 0, then the solution to the simultaneous equations includes the values of b that are not only the least-square estimators, but also meet the condition that Σbi = 0.
Of course, all these properties of Σ(b) = 0 are contingent on the absorbances of all the wavelengths in the model varying in a coordinated manner, that is, any changes must be in the same direction and by the same amount. By that definition, then, random noise will not be rejected.
The Meaning of λ
One question remains: what is the meaning of λ? There are several on-line discussions of the Lagrange method, some of which discuss the significance and meaning of λ (13,15).
Some of the explanations are somewhat dismissive of this: “The value of λ isn’t really important to determining if the point is a maximum or a minimum so often we will not bother with finding a value for it” (15).
Others give a mathematical explanation, not addressing the physical meaning of the value of lambda as it pertains to the problem stated. For example, “λk is the rate of change of the quantity being optimized as a function of the constraint parameter. As examples,
in Lagrangian mechanics the equations of motion are derived by finding stationary points of the action, the time integral of the difference between kinetic and potential energy” (13).
Neither of those explanations is particularly useful to us. Sometimes the meaning of a variable becomes clear when that variable is provisionally assigned an extreme value, just for the purpose of elucidating its meaning and significance. On the other hand, if we examine equation 11 closely, we notice that λ multiplies Σbi. Here we can apply a general procedure that enables us to gain insight to the meaning of mathematical quantities. The “trick” is to consider taking a property to an extreme value to see what happens. Thus, in our current case we consider setting λto zero. If λ = 0 then the sum of the coefficients is immaterial, since the product withλ is zero and has no effect on the value of the computation. In other words, if λ = 0, then the constraint disappears, and the result of the computation is the same as that of the corresponding unconstrained problem. Non-zero values for λ then, indicate the strength of the constraint. If λ is small, then the values of the sum of squares of the bi will be their least square values. If λ is large, then values of the coefficients will be dominated by the constraint, and the sum of the coefficients will equal zero regardless of the ability of the coefficients to accurately predict the values of the constituent. Hopefully, the data will be such that a good compromise can be made. Our experience, though limited, has shown this to be the case.
References
(1) Mark, H.; Workman, J. Data Transforms in Chemometric Calibrations: Application to Discrete-Wavelength Models, Part 1: The Effect of Intercorrelation of the Spectral Data. Spectroscopy 2022, 37 (2), 16–18, 54. DOI: 10.56530/spectroscopy.wp6284b9
(2) Mark, H.; Workman, J. Data Transforms in Chemometric Calibrations: Simple Variations of MLR, Part 2. Spectroscopy 2022, 37 (7), 14–19. DOI: 10.56530/spectroscopy.cg7965x1
(3) The New York/New Jersey Section of the Society for Applied Spectroscopy. NYSAS Gold Medal Award. The New York/New Jersey Section of the Society for Applied Spectroscopy 2023. https://nysas.org/past-gold-medal-winners/ (accessed 2023-08-14)
(4) Ciurczak, E. W.; Igne, B.; Workman, J.; Burns, D. Handbook of Near-Infrared Analysis, 4th Edition; CRC Press, 2021, pp. 9–43.
(5) Schuster, A. XXII. The influence of radiation on the transmission of heat. Phil. Mag. 1903, 5 (26), 243–257. DOI: 10.1080/14786440309462919
(6) Schuster, A. Radiation through a foggy atmosphere. Astrophys. J. 1905, 21, 1. https://adsabs.harvard.edu/full/1905apj....21....1S (accessed 2023-08-14)
(7) Kortum, G. Reflectance Spectroscopy: Principles, Methods, Applications; Springer-Verlag, 1969.
(8) Wendlandt, W. W.; Hecht, H. G. Reflectance Spectroscopy; John Wiley & Sons, 1966.
(9) Dahm, D. J.; Dahm, K. D. Interpreting Diffuse Reflectance and Transmittance: A Theoretical Introduction to Absorption Spectroscopy of Scattering Materials; IM Publications, 2007.
(10) Meyerhofer, T. G.; Oleksii, I.; Kutsyk, A.; Popp, J. Beyond Beer’s Law: Quasi-Ideal Binary Liquid Mixtures. Appl. Spectrosc. 2022, 76 (1), 92–104. DOI: 10.1177/00037028211056293
(11) Mark, H.; Workman, J. Chemometrics in Spectroscopy, 2nd edition; Elsevier, 2018.
(12) Mark, H. Principles and Practice of Spectroscopic Calibration; John Wiley & Sons, 1991.
(13) Wikipedia. Lagrange multiplier. Wikipedia 2023. https://en.wikipedia.org/wiki/Lagrange_multipliers (accessed 2023-08-14)
(14) Taylor, A. E. Advanced Calculus; Ginn and Company, 1955.
(15) Paul’s Online Notes. Section 14.5 : Lagrange Multipliers. Paul Dawkins 2023. https://tutorial.math.lamar.edu/classes/calciii/lagrangemultipliers.aspx (accessed 2023-08-14)


Jerome Workman, Jr. serves on the Editorial Advisory Board of Spectroscopy and is the Senior Technical Editor for LCGC and Spectroscopy. He is the co-host of the Analytically Speaking podcast and has published multiple reference text volumes, including the three-volume Academic Press Handbook of Organic Compounds, the five-volume The Concise Handbook of Analytical Spectroscopy, the 2nd edition of Practical Guide and Spectral Atlas for Interpretive Near-Infrared Spectroscopy, the 2nd edition of Chemometrics in Spectroscopy, and the 4th edition of The Handbook of Near-Infrared Analysis. ●



Howard Mark serves on the Editorial Advisory Board of Spectroscopy, and runs a consulting service, Mark Electronics, in Suffern, New York. Direct correspondence to: SpectroscopyEdit@mmhgroup.com ●







Newsletter
Get essential updates on the latest spectroscopy technologies, regulatory standards, and best practices—subscribe today to Spectroscopy.


AI-Powered Fusion Model Improves Detection of Microplastics in the Atmosphere
July 17th 2025Researchers from Nanjing University of Information Science & Technology have introduced a breakthrough AI-enhanced multimodal strategy for real-time detection of polyamide microplastics contaminated with heavy metals.

High-Speed Immune Cell Identification Using New Advanced Raman BCARS Spectroscopy Technique
July 16th 2025Irish researchers have developed a lightning-fast, label-free spectroscopic imaging method capable of classifying immune cells in just 5 milliseconds. Their work with broadband coherent anti-Stokes Raman scattering (BCARS) pushes the boundaries of cellular analysis, potentially transforming diagnostics and flow cytometry.

AI-Powered Raman with CARS Offers Laser Imaging for Rapid Cervical Cancer Diagnosis
July 15th 2025Chinese researchers have developed a cutting-edge cervical cancer diagnostic model that combines spontaneous Raman spectroscopy, CARS imaging, and artificial intelligence to achieve 100% accuracy in distinguishing healthy and cancerous tissue.


Drone-Mounted Infrared Camera Sees Invisible Methane Leaks in Real Time
July 9th 2025Researchers in Scotland have developed a drone-mounted infrared imaging system that can detect and map methane gas leaks in real time from up to 13.6 meters away. The innovative approach combines laser spectroscopy with infrared imaging, offering a safer and more efficient tool for monitoring pipeline leaks and greenhouse gas emissions.

How Spectroscopy Drones Are Detecting Hidden Crop Threats in China’s Soybean Fields
July 8th 2025Researchers in Northeast China have demonstrated a new approach using drone-mounted multispectral imaging to monitor and predict soybean bacterial blight disease, offering a promising tool for early detection and yield protection.

